SIDGAN: High-Resolution Dubbed Video Generation via Shift-Invariant Learning
Oct 1, 2023·,,,,,,,,,·
0 min read
Urwa Muaz
Won-Dong Jang
Rohun Tripathi
Santhosh Mani
Wenbin Ouyang
R. Gadde
Baris Gecer
Sergio Elizondo
Reza Madad
Naveen Nair
Abstract
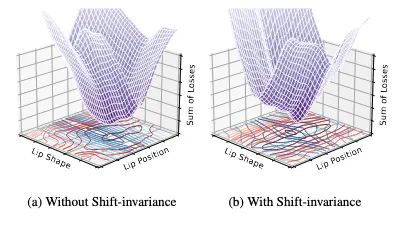
Dubbed video generation aims to accurately synchronize mouth movements of a given facial video with driving audio while preserving identity and scene-specific visual dynamics, such as head pose and lighting. Despite the accurate lip generation of previous approaches that adopts a pre-trained audio-video synchronization metric as an objective function, called Sync-Loss, extending it to high-resolution videos was challenging due to shift biases in the loss landscape that inhibit tandem optimization of Sync-Loss and visual quality, leading to a loss of detail.To address this issue, we introduce shift-invariant learning, which generates photo-realistic high-resolution videos with accurate Lip-Sync. Further, we employ a pyramid network with coarse-to-fine image generation to improve stability and lip syncronization. Our model outperforms state-of-the-art methods on multiple benchmark datasets, including AVSpeech, HDTF, and LRW, in terms of photo-realism, identity preservation, and Lip-Sync accuracy.
Type
Publication
In IEEE International Conference of Computer Vision